
按『个人 Wiki』风格整理的学习笔记
| Compute Capability | Architecture Name | Release Year |
|---|---|---|
| 9.0 | Hopper | 2022 |
| 8.0 | Ampere | 2020 |
| 7.5 | Turing | 2018 |
| 7.0 | Volta | 2017 |
| 6.x | Pascal | 2016 |
| 5.x | Maxwell | 2014 |
| 3.0 | Kepler | 2012 |
| 2.0 | Fermi | 2010 |
| 1.0 | Tesla | 2006 |
| 物理单元 | 逻辑单元 |
|---|---|
| Graphics Processing Units | grid |
| Streaming Multiprocessor | block |
| Streaming Processor | thread |
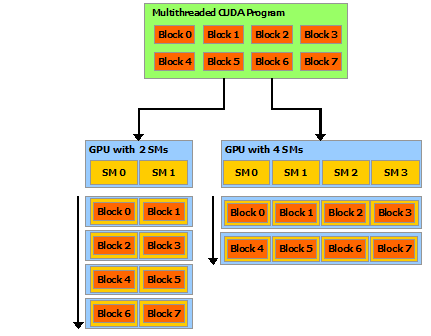
同一 grid 内的各 blocks 同构且相互独立,以允许不同的运行顺序:
每个 thread 启动时,有以下 dim3 型变量可用:
threadIdx 用于在当前 block 内索引 threadblockIdx 用于在当前 grid 内索引 blockblockDim 用于表示当前 block 的维数,即其所含 threads 的数量gridDim 用于表示当前 grid 的维数,即其所含 blocks 的数量类型 dim3 的定义大致为
struct dim3 {
int x, y, z;
dim3(int xx = 1, int yy = 1, int zz = 1)
: x(xx), y(yy), z(zz) {}
};
#include <cuda_runtime.h>
int main() {
// ...
int deviceCount = 0;
cudaGetDeviceCount(&deviceCount);
int dev = 0;
cudaSetDevice(dev);
int driverVersion = 0;
cudaDriverGetVersion(&driverVersion);
int runtimeVersion = 0;
cudaRuntimeGetVersion(&runtimeVersion);
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
// ...
}
其中 cudaDeviceProp 型变量的主要成员包括:
| 类型 | 成员名 | 含义 | 典型值 (A100 80GB PCIe) |
|---|---|---|---|
int | clockRate | (deprecated) clock frequency in kHz | 1.41 GHz |
int | l2CacheSize | size of L2 cache in bytes | 41943040 |
int | major, minor | major and minor compute capability | 12.2 |
int | maxThreadsPerMultiProcessor | maximum resident threads per multiprocessor | 2048 |
int | maxThreadsPerBlock | maximum number of threads per block | 1024 |
int | memoryclockRate | (deprecated) peak memory clock frequency in kHz | 1512 MHz |
int | memoryBusWidth | global memory bus width in bits | 5120-bit |
int | multiProcessorCount | number of multiprocessors on device | 108 |
char[256] | name | ASCII string identifying device | "NVIDIA A100 80GB PCIe" |
int | regsPerBlock | 32-bit registers available per block | 65536 |
int | sharedMemPerBlock | shared memory available per block in bytes | 49152 |
size_t | totalGlobalMem | global memory available on device in bytes | 79.15 GBytes |
int | warpSize | warp size in threads | 32 |
也可以用 nvidia-smi 命令获取 GPU 信息:
# 显式已每个已安装 GPU 的 ID
nvidia-smi -L
# 显式 MEMORY | UTILIZATION | CLOCK 相关信息
nvidia-smi -q -i 0 -d [ MEMORY | UTILIZATION | CLOCK ]
hello.cu 关键行:
/* ... */
#include <cuda.h> /* CUDA's header */
/* Device code: runs on GPU */
__global__ void Hello() {
printf("Hello, world from thread[%d][%d][%d] in block[%d][%d][%d]\n",
threadIdx.x, threadIdx.y, threadIdx.z,
blockIdx.x, blockIdx.y, blockIdx.z);
}
/* Host code: runs on CPU */
int main(int argc , char* argv[]) {
/* ... */
/* Invoke the kernel function running on (n_block * n_thread_per_block) threads: */
Hello<<< n_block, n_thread_per_block >>>();
/* Wait for GPU to finish: */
cudaDeviceSynchronize();
/* ... */
}
编译、运行:
nvcc -o hello.exe hello.cu
./hello.exe 4 2
可能的结果:
$ ./hello.exe 4 2
Hello, world from thread[0][0][0] in block[0][0][0]
Hello, world from thread[1][0][0] in block[0][0][0]
Hello, world from thread[0][0][0] in block[3][0][0]
Hello, world from thread[1][0][0] in block[3][0][0]
Hello, world from thread[0][0][0] in block[2][0][0]
Hello, world from thread[1][0][0] in block[2][0][0]
Hello, world from thread[0][0][0] in block[1][0][0]
Hello, world from thread[1][0][0] in block[1][0][0]
其中 __global__ 为函数类型修饰符,表示该函数被 host 调用(CC >= 3 也可被 device 调用)、在 device 上执行,且返回值类型必须是 void。 除此之外,还有另外两种函数类型修饰符(可以同时使用):
__device__ 表示该函数只能被 device 调用、在 device 上执行。__host__ 表示该函数只能被 host 调用、在 host 上执行,可以缺省。绝大多数 CUDA 函数的返回值类型都是 cudaError_t,其值可用以下函数转换成字符串:
char* cudaGetErrorString(cudaError_t error);
Cheng (2014) 提供了以下封装:
#define CHECK(call) {
const cudaError_t error = call;
if (error != cudaSuccess) {
printf("Error: %s:%d, ", __FILE__, __LINE__);
printf("code:%d, reason: %s\n", error, cudaGetErrorString(error));
exit(1);
}
}
nvprof ProfilerCPU 计时器:
#include <sys/time.h>
double cpuSecond() {
struct timeval tp;
gettimeofday(&tp, NULL);
return ((double)tp.tv_sec + (double)tp.tv_usec*1.e-6);
}
用 nvprof 统计调用次数及运行时间:
nvprof [nvprof_args] <app> <app_args>
相当于对 C 数组 T a[dim.z][dim.y][dim.x] 按 a[idx.z][idx.y][idx.x] 索引的地址偏移。
size_t _ID(dim3 idx, dim3 dim) {
return idx.x + (idx.y + idx.z * dim.y) * dim.x;
}
size_t threadID() {
return _ID(threadIdx, blockDim);
}
size_t blockID() {
return _ID(blockIdx, gridDim);
}
定义:不可分的读-改-写操作。
后缀决定该操作原子性的 scope:
cuda::thread_scope_device_block 的版本,scope 为 cuda::thread_scope_block,需要 compute capability >= 6.0_system 的版本,scope 为 cuda::thread_scope_system,需要 compute capability >= 7.2// compute capability >= 2.x
__device__ float atomicAdd(float* address, float val);
// compute capability >= 6.x
__device__ double atomicAdd(double* address, double val);
// Compare-And-Swap
T atomicCAS(T* addr, T comp, T val) {
// Effectively do the following in an atomic way.
T old = *addr;
*addr = (old == comp ? val : old);
return old;
}
| Name | Effect |
|---|---|
atomicAdd | *addr += val |
atomicSub | *addr -= val |
atomicExch | *addr = val |
atomicMin | *addr = min(*addr, val) |
atomicMax | *addr = max(*addr, val) |
atomicInc | *addr < val ? ++*addr : *addr = 0 |
atomicDec | *addr && *addr <= val ? --*addr : *addr = val |
atomicAdd | *addr &= val |
atomicOr | *addr |= val |
atomicXor | *addr ^= val |
CUDA 提供一种高效同步同一 block 内所有 threads 的机制:
__device__ void __syncthreads(void);
__host__ __device__ cudaError_t cudaMalloc(void **devPtr, size_t size);
__host__ __device__ cudaError_t cudaFree(void *ptr)
/* 自带 sync */
__host__ cudaError_t cudaMemcpy(void* dst, const void* src, size_t count,
cudaMemcpyKind kind/* cudaMemcpyHostToDevice or cudaMemcpyDeviceToHost */);
__host__ cudaError_t cudaMallocManaged(void **devPtr, size_t size
unsigned flags = cudaMemAttachGlobal);
cudaFree() 释放。compuate capability >= 3.0,但若 compuate capability < 6.0,则不能同时被 host 与 device 访问。利用全局 __managed__ 变量获得 kernel 计算结果:
__managed__ ini sum;
__global__ void Add(int x, int y) {
sum = x + y; // 在 device 中更新
}
int main() {
sum = -5; // 在 host 中初始化
Add<<< 1, 1 >>>(2, 5);
cudaDeviceSynchronize();
printf("sum == %d\n", sum); // 在 host 中输出结果
return 0;
}
compuate capability >= 3.0
具有连续 threadID 且属于同一 block 的一组 threads,以 SIMD 模式运行(不同 warps 可以独立运行)。
int warpSize /* currently 32 */
/* 当前 thread 在其所属 warp 内的编号: */
int lane = threadID % warpSize;
同一 warp 内的threads 可以读取其他 threads 的寄存器:
__device__ float __shfl_down_sync(
unsigned mask/* 参与 shuffle 的 threads, e.g. 0xFFFFFFFF */,
float val/* 当前 thread(即 lane = lane_caller)传入的值 */,
unsigned diff/* 返回 lane = lane_caller + diff 传入的 val */,
int witdh = warpSize)
⚠️ 若 lane_caller + diff
> max_lane_in_this_warp,则返回值未定义⚠️>= warpSize,则返回当前 thread 传入的 val/* 所有 threads 都参与求和,只有 land = 0 的那个 thread 的返回值正确 */
__device__ float WarpSum(float val) {
for (int diff = warpSize / 2; diff > 0; diff /= 2) {
var += __shfl_down_sync(0xFFFFFFFF, var, diff);
}
return var;
}
由同一 SM 内的 SPs 共享的高速缓存,逻辑上分为 32 banks(a[i] 与 a[i + 32] 属于同一 bank):
/* 模仿 WarpSum,所有 threads 的返回值都正确 */
__device__ float SharedSum(float vals[]) {
int my_lane = threadID() % warpSize;
for (int diff = warpSize / 2; diff > 0; diff /= 2) {
int source = (lane + diff) % warpSize;
vars[my_lane] += vars[source]; /* 以 SIMD 方式运行,没有竞争 */
}
return vars[my_lane];
}
其中 vals 应显式定义在 shared memory 中:
// 显式指定数组大小
__shared__ float vals[32];
// 运行期由 SharedSum<<< n_block, n_thread_per_block, n_byte >>> 指定数组大小
extern __shared__ float vals[];
CUDA API 分两类:
cudaStream_t【Stream】指由 host 发起、在 device 上运行的异步操作(含 host–device 数据迁移、kernel 启动等)序列。
Streams 分两类:
典型用例:
// 在 host 上分配 pinned / non-pageable / page-locked memory:
cudaError_t cudaMallocHost(void **ptr, size_t size);
cudaError_t cudaHostAlloc(void **pHost, size_t size, unsigned int flags);
// 构造 cudaStream_t:
cudaStream_t stream[kStreams];
for (int i = 0; i < kStreams; i++) {
cudaStreamCreate(streams + i);
}
for (int i = 0; i < kStreams; i++) {
// 异步地 host-to-device 迁移数据:
cudaMemcpyAsync(device_mem, pinned_host_mem, n_byte,
cudaMemcpyHostToDevice, streams[i]);
// 启动 kernel:
MyKernel<<<grid, block, sharedMemSize, stream>>>(args);
// 异步地 device-to-host 迁移数据:
cudaMemcpyAsync(pinned_host_mem, device_mem, n_byte,
cudaMemcpyDeviceToHost, streams[i]);
}
for (int i = 0; i < kStreams; i++) {
// 显式同步:
cudaStreamSynchronize(streams[i]);
// 阻塞,直到该 stream 中的操作全部完成
cudaStreamQuery(streams[i]);
// 非阻塞,返回 cudaSuccess 或 cudaErrorNotReady
}
// 析构 cudaStream_t:
for (int i = 0; i < kStreams; i++) {
cudaStreamDestroy(streams[i]);
}
⚠️ 受 PCIe bus 限制,同一 device 上至多可同时执行 1 个 host-to-device、1 个 device-to-host 数据传输操作。
cudaEvent_t【Event】指 stream 中的特定时间节点,可用于
典型用例:
// 构造 cudaEvent_t:
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// 记录事件:
cudaEventRecord(start, stream/* 缺省则为 0 */);
/* ... 该 stream 中的其他操作 */
cudaEventRecord(stop, stream/* 缺省则为 0 */);
// 用 event 同步:
cudaEventSynchronize(stop);
// 获取时间差:
float elapsedTime; // 单位为 ms
cudaEventElapsedTime(&elapsedTime, start, stop); // 不必记录于同一 stream
// 析构 cudaEvent_t:
cudaEventDestroy(event);
其中 cudaEventCreate(&event) 等价于
cudaEventCreateWithFlags(&event, cudaEventDefault);
这样创建的 cudaEvent_t 遇到 cudaEventSynchronize(stop) 时,会让 CPU 空转等待。
为避免浪费 CPU 资源,第二个参数可以替换为
cudaEventBlockingSync,表示让渡 CPU 核心;cudaEventDisableTiming,表示无需存储时间数据;cudaEventInterprocess,表示创建跨进程事件。Streams 分类:
// stream_0 为默认的 NULL stream,stream_[12] 均为 blocking streams
cudaStreamCreate(&stream_1);
cudaStreamCreateWithFlags(&stream, cudaStreamDefault);
kernel_1<<<1, 1, 0, stream_1>>>();
kernel_2<<<1, 1>>>(); // 等待 kernel_1 完成才启动
kernel_3<<<1, 1, 0, stream_2>>>(); // 等待 kernel_2 完成才启动
cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking);
同步分类:
cudaDeviceSynchronize(void)、cudaStreamSynchronize(stream)、cudaEventSynchronize(event)、cudaEventWaitEvent(stream, event) 等。cudaMallocHost()、cudaHostAlloc() 等,及 cudaMemcpy() 等涉及 device 内存的操作。